病害虫の発生予測に使われる統計モデルと機械学習手法の比較
要約
病害虫発生予察事業のデータに対して、代表的な機械学習および統計モデル手法により予測結果を比較したところ、決定木とランダムフォレストの成績が最も良い。予測にあたっては、データサイズや地域的な偏りを考慮した手法選択が必要であると考えられる。
- キーワード : 機械学習、統計、病害虫発生予測、ランダムフォレスト、ベイズモデル
- 担当 : 基盤技術研究本部・農業情報研究センター・AI研究推進室・確率モデルユニット
- 代表連絡先 :
- 分類 : 研究成果情報
背景・ねらい
農作物病害虫の発生を予測することは農業における主要なニーズの一つである。近年、機械学習の手法が急速に発達し、病害虫の発生予測にも使われるようになっている。しかし統計モデルや機械学習手法についてそれらの特徴やデータに対する適性などについてはあまり整理されていない。本研究では発生予察事業で得られた農作物病害虫のモニタリングデータを用いて、2つの統計モデルと7つの機械学習手法の特徴を調べる。対象農作物は、重要作物であり、かつ、モニタリングされている病害虫も多い4品目(ナス、キュウリ、トマト、イチゴ)とする。これらについて病害虫の種類、調査項目(株あたり虫数など)に応じて異なる計203データセットを用いる。それぞれのデータに対し、統一された方法で9手法をあてはめ、結果を比較する。
成果の内容・特徴
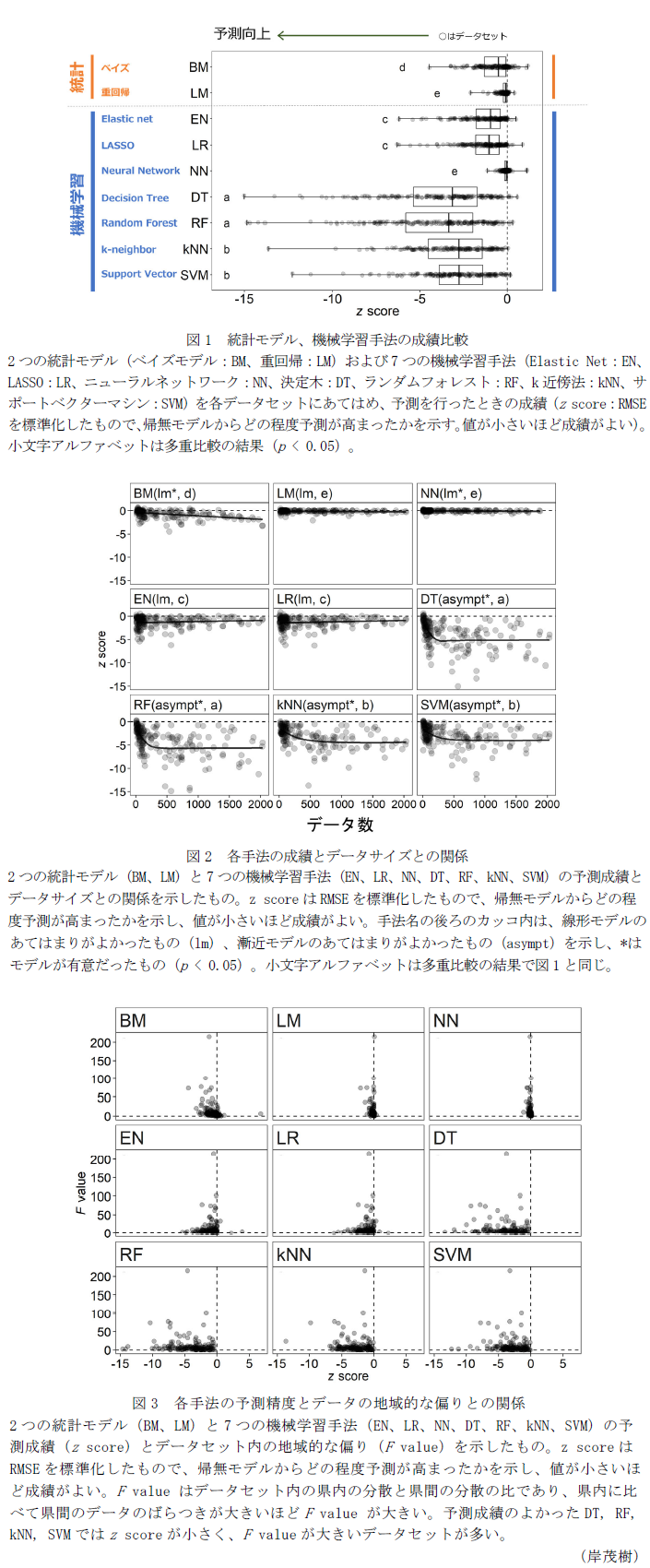
- 機械学習の決定木(DT)とランダムフォレスト(RF)が、最もよい成績を示す。(図1)。k-近傍法(kNN)とサポートベクターマシン(SVM)が続く。一方、統計モデルの重回帰分析や機械学習のニューラルネットワーク(NN)は他の手法に劣後する。DTとRFはいずれも決定木を使う点でアルゴリズムが似通っており、kNNとSVMはいずれもノンパラメトリックな分類アルゴリズムである点が共通である。今回用いたNNは2層のみのため、重回帰分析と似た結果を示す。これらのことから予測性能はアルゴリズムに依存することが示唆される。また、品目に応じた違いはみられない。
- 各データセットについて予測性能とデータセットのサイズ(記録回数)の関係をみると、DT、RF、kNN、SVMはいずれもデータセットのサイズが増大するとともに予測成績は漸近する。一方、ベイズモデルではサイズの増大とともに予測成績が向上する(図2)。
- 今回用いたデータセットはサイズの偏りだけでなく地域的な偏りも大きい。各データセットについて県内の分散と県間の分散の比からF値をとると、DT、RF、kNN、SVMは他の手法に比べてF値が大きなデータセットでも比較的予測精度がよい(図3)。このことから、今回の成績上位の手法は地域的なデータの偏りにも比較的強いことがうかがえる。病害虫の発生予測をする場合には、データのサイズや地域的な偏りを考慮して手法を選択すべきであると考えられる。
成果の活用面・留意点
- 解析に用いたデータおよびコードは適切な許可手続きを経て、オープンアクセスとなっており、これらのコードを活用して、予測手法の性能比較ができる。 Open Science Framework URL: https://osf.io/ 2024年1月24日確認。 Statisticalmodels_vs_Machinelearning URL: https://osf.io/g72ac/ 2023年1月24日確認。
- ある病害虫の過去のモニタリングデータを元に未来の発生予測を行う場合、本研究のコード(上記参照)を用いて予測成績を手法間で比較することができる。
- 今回用いたデータセットではRF、DTの成績がよかったが、他のデータセットを用いたときに同様の結果になるとは限らない点に留意が必要である。
具体的データ
その他
- 予算区分 : 農林水産省(戦略的プロジェクト研究推進事業:AIを活用した病害虫診断技術の開発)、環境省(環境研究総合推進費)
- 研究期間 : 2020~2023年度
- 研究担当者 : 岸茂樹、孫建強、川口章、越智直、吉田めぐみ、山中武彦
- 発表論文等 : Kishi S. et al. (2023) R. Soc. Open Sci 10:230079
Doi.org/10.1098/rsos.230079