予測誤差を小さくするための並列型モデル合成法
※アーカイブの成果情報は、発表されてから年数が経っており、情報が古くなっております。
同一分野の研究については、なるべく新しい情報を検索ください。
要約
幾つかの方法で作成されたモデルが与える推定値から1つを採用する際に、推定値を必要とする予測変数の値における予測誤差の絶対値が最も小さくなる推定値を選ぶ。これによって、単独のモデルを用いる場合に比べて予測誤差が小さい推定値が得られる。
- キーワード:ノンパラメトリック回帰、モデル選択、モデル合成、予測
- 担当:中央農研・農業情報研究部・生産支援システム開発チーム、明治大学・理工学部
- 連絡先:電話029-838-8975、電子メール takezawa@affrc.go.jp
- 区分:関東東海北陸農業・情報研究、共通基盤・情報研究
- 分類:科学・参考
背景・ねらい
これまでのモデル選択は、同じデータを用いて複数のモデルを作成し、何らかのモデル選択基準を利用してその中の1つを採用 するものである。しかし、予測変数の値によって採用すべきモデルが異なることもあり得る。目的変数の振る舞いが予測変数の領域によって多様に変化する場合 には、それぞれのモデルが得意とする領域があると見なされるからである。この見方を生かしたアルゴリズムをノンパラメトリック回帰に応用すれば、従来のも のよりも予測誤差が小さい推定値を与えるモデルが実現することが期待できる。
成果の内容・特徴
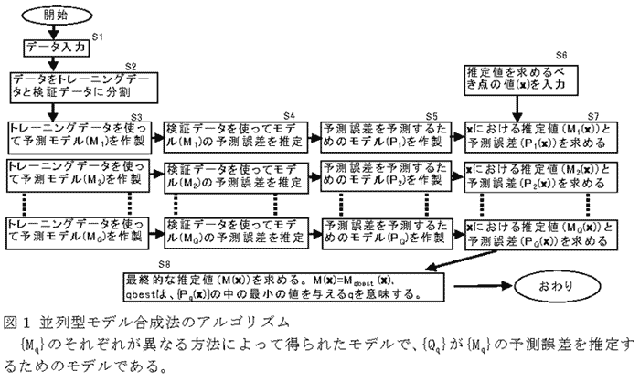
- 並列型モデル合成法のアルゴリズムの基本的な形態は図1である。
- 並列型モデル合成法の実行例として、「青果市況データベース」NAPASS(Nationwide Agricultural Products Analysis Support System)から取り出した東京都太田市場のだいこんのデータを利用する。
- 並列型モデル合成の機能を調べるために用いたデータは、表1に示した3種類である。それぞれのデータは、9つの予測変数(曜日、旬、入荷量など)と1つの目的変数(当日の価格)からなっている。
- モデル作製手法として用いたのは、CART(樹形モデル)、MARS(Multivariate Adaptive Regression Splines)、TreeNet、ニューラルネットワーク(バックプロパゲーションを用いたもの)の4つである。
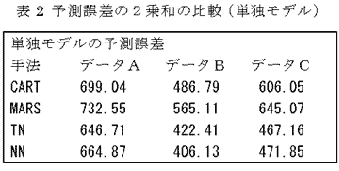
- 予測誤差の2乗和を比較した結果が表2と表3で ある。ここで、「単独モデル」とは、それぞれのモデル作製手法を単独に用いた場合である。「合成モデル」とは、{Mq}を得るための手法として(4)で示 した4つの方法を用い、{Pq}を得るための手法としてCARTを用いた場合である。並列型モデル合成法によって予測誤差が減少していることが分かる。
成果の活用面・留意点
- それぞれのモデル(図1の{Mq}のそれぞれ)を作製する手法としていろいろなものを利用することができる。
- それぞれのモデル(図1の{Pq}のそれぞれ)として、他のデータを使って作製された既製のモデルを利用することも考えられる。
- 並列型モデル合成法には様々な発展的な形態が考えられるので、それらを比較して選択すると更に優れた予測が可能になる。
具体的データ


その他
- 研究課題名:モデル作成のための対話型プログラムの開発
- 課題ID:03-04-05-01-07-03
- 予算区分:交付金
- 研究期間:2001~2003年度
- 研究担当者:竹澤邦夫、南石晃明、橋本大輔(明治大学)、大滝 厚(明治大学)
- 発表論文等:1)特許出願 特願2003-372638, 2003年10月31日