農業用語形態素解析サーバ
※アーカイブの成果情報は、発表されてから年数が経っており、情報が古くなっております。
同一分野の研究については、なるべく新しい情報を検索ください。
要約
農業用語辞書を組み込むことにより、農業関連文書向けに単語への分割(形態素解析)の機能を提供するサーバを開発した。このサーバを利用することにより、農業関連の専門用語を多く含む文書を取り扱う場合に、専門用語を単語として抽出できる。
- キーワード:農業用語、テキストマイニング、形態素解析
- 担当:中央農研・農業情報研究部・グリッドコンピューティングチーム、モデル開発チーム
- 連絡先:電話029-838-7176、電子メールhoryu@affrc.go.jp
- 区分:共通基盤・情報研究
- 分類:科学・参考
背景・ねらい
ネットワークを通じて大量のテキストデータが利用できるようになり、これらのテキストデータを有効に利用するためには、テキストマイニングの支援が不可欠となっている。テキストマイニングは、農業関連分野においても、例えば消費者への直接販売を導入している経営体等が顧客アンケートの集計により消費者ニーズを数量的に把握するなどの場面で有効なツールとなり得る。
テキストマイニングの過程の一部である形態素解析では、辞書を参照し、その中の単語との照合を行って、単語への分割や語形変化の解析を行う。このため、用いる辞書によって形態素解析の結果は変化する。専門用語を多く含む文書を対象に形態素解析を行う場合には、専門用語の辞書を組み込むことで、これらの専門用語を単語として抽出できる。抽出された専門用語が、その後の処理の結果を改善する場合もあると考えられる。こうした事情をふまえ、農業関連分野における日本語の文書のテキストマイニングを支援するツールとして、農業用語辞書を用いた形態素解析の機能を提供するサーバの開発を行った。このサーバを利用することにより、農業関連の専門用語を多く含む文書を対象としている場合には、形態素解析の結果として辞書に含まれる農業関連の専門用語が現れるようになる。
成果の内容・特徴
- 本サーバは利用者から送られた文字列を対象に形態素解析を行い、解析結果を利用者に返すシステムである。形態素解析の過程で、農業関連の専門用語を認識する。
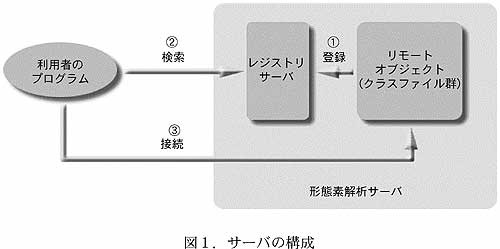
- 利用者は、テキストマイニングのプログラム中で本サーバへの接続に必要な命令を記述し、インターネットを経由してこのサーバに接続する。サーバへの接続にはJavaRMIの機構を用いる。サーバの構成および接続の過程を図1に示した。
- 形態素解析プログラムには「茶筌」を、一般用語の辞書に情報処理振興事業協会品詞体系日本語辞書(IPADIC)を使用している。農業用語辞書として、大塚・北村(1999)による約57,000語(IPADICとの重複等を除いて整理した後の語数)の辞書を使用している。
- 解析結果は形態素およびその属性の集合であり、図2に示したようなjava.lang.Stringの文字列として返される。
成果の活用面・留意点
- 情報抽出、テキスト自動要約、テキスト自動分類などのテキストマイニングを行うシステムに部品としてこのサーバを組み込むことができる。
- 本サーバは、プログラム中に組み込むシステムであり、直接の利用者としては主にプログラムの開発者を想定している。
具体的データ

その他
- 研究課題名:語彙体系およびエージェント技術による分散農業情報統合システムの開発
- 課題ID:03-04-04-01-03-03
- 予算区分:協調システム、交付金
- 研究期間:22001~2003年度
- 研究担当者:法隆大輔、深津時広、大塚 彰、木浦卓治、平藤雅之、二宮正士
- 発表論文等:法隆ら(2004) 農業情報研究13(2):127-138.