次世代スーパースムーザ
※アーカイブの成果情報は、発表されてから年数が経っており、情報が古くなっております。
同一分野の研究については、なるべく新しい情報を検索ください。
要約
平滑化を行うための手段としてこれまで広く使われてきたスーパースムーザの問題点を解決した平滑化手法である。データ数が多いときや、データが複雑な振る舞いをするときにも適切な平滑化が実現する。
- キーワード:スーパースムーザ、ノンパラメトリック回帰、平滑化、平滑化パラメータ
- 担当:中央農研・農業情報研究部・専門領域研究官
- 連絡先:電話029-838-8948、電子メールtakezawa@affrc.go.jp
- 区分:共通基盤・情報研究
- 分類:科学・参考
背景・ねらい
データの性質が局所的に大きく変化する場合に対応する平滑化手法としてスーパースムーザが広く使われている。しかし、スーパース ムーザは、計算量を少なくすることに力点を置いた手法であるため、多彩な性質を持つ大量のデータを処理することが要求される現在の事情にそぐわない。そこ で、計算量がいくらか多くはなるけれども、ノンパラメトリック回帰の基本的な概念に即し、局所的なデータの性質を適切に反映した平滑化を行うための手法を 開発する。
成果の内容・特徴
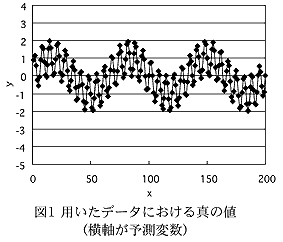
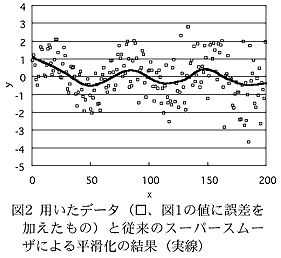
- 予測変数の値が大きくなるに従って誤差の大きさが増すシミュレーションデータを用いて本手法の機能を示す。図1がシミュレーションデータにおける真の値である。これらの値に、予測変数の値が大きくなるにつれて大きな誤差を加えた結果が、図2の□で示されている値である。これを従来のスーパースムーザを用いて平滑化した結果が、図2において実線で描かれている。従来法では、全体的に強い平滑化が施されており、誤差の大きさの局所的な変化を反映していない。
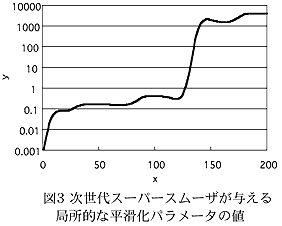
- 図3は、 次世代スーパースムーザが与える、局所的な平滑化パラメータの値である。本手法では、誤差が大きい領域において、データの細かな動きをエイリアシング誤差 (データの本質的な挙動ではあるけれども誤差として扱うべきもの)と見なした方が優れた推定値が得られることを示している。
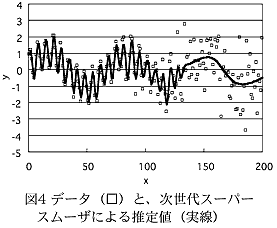
- 図4が、図3に 示した平滑化パラメータの値を用いた平滑化を実行したときに得られる推定値とデータを図示したものである。このシミュレーションにおいては予測変数の値が 大きくなるにしたがって誤差が大きくなっているので、本手法は、予測誤差の値が小さい領域ではデータの細かな動きを反映した推定値をもたらし、予測誤差の 値が大きい領域では強い平滑化を施すことによってデータの細かな変動を除いた推定値を与えている。
- 乱数の初期値を変えて同様のシミュレーションを繰り返した結果は、本手法が与える推定値は従来のスーパースムーザが与える推定値よりも真の値に近いことを示している。
成果の活用面・留意点
- 本方法は、ノンパラメトリック回帰の基本的な概念だけを利用していて、乱数を用いた計算は必要としないので、信頼性が高い。
- ここで用いた計算と作図のためにはS-Plusを使用した。しかし、他の言語に移し替えることも容易である。
- 作製したS-Plusプログラムをいつでも配布できる。
具体的データ
その他
- 研究課題名:農業生産支援のための高精度予測モデルの開発
- 課題ID:03-04-05-01-13-04
- 予算区分:交付金
- 研究期間:2004∼2006年度
- 研究担当者:竹澤邦夫
- 発表論文等:
(1) Takezawa(2005) Introduction to Nonparametric Regression. John Wiley & Sons. pp.538
(2) 竹澤 (2006) 応用統計学 Vol.34, No.3 (平成18年3月末にページ確定)