超大量文書・超大型辞書でも利用できる概念検索エンジン
※アーカイブの成果情報は、発表されてから年数が経っており、情報が古くなっております。
同一分野の研究については、なるべく新しい情報を検索ください。
要約
文書群から意味概念が類似の文書を効率的に検索する概念検索エンジン。既開発のインデクス作成方式等を全面的に改良し、インデクス演算速度が約100倍で、100万文書、辞書サイズ50万単語でも実用的に利用できる。
- キーワード:テキストマイニング、農林水産現地情報、成果情報、SDD
- 担当:中央農研・農業情報研究部・グリッドコンピューティングチーム,モデル開発チーム
- 連絡先:電話029-838-8972、電子メールsnino@affrc.go.jp
- 区分:共通基盤・情報研究
- 分類:科学・参考
背景・ねらい
これまでに、テキストで蓄積される膨大な農業情報から、類似した内容の文書を効率的に発見し意志決定に役立てるしくみとして、概念 検索エンジンを開発した(平成10年成果情報)。しかし、検索用のインデクス作成に多大な計算能力が必要で、同時に扱える文書数や、文書から単語を切り出 す辞書のサイズに制約があった。そこで、インデクス構築のための行列演算方式を全面的に見直すことや、文書データベースの複数計算機への分散化によって、 100万文書、辞書サイズ50万語程度でも実用的に利用できる概念検索エンジンを開発する。
成果の内容・特徴
- 既開発の概念検索エンジンで検索インデクス作成に用いたSVD-LSI(Singular Value Decomposition特異値分解- Latent Semantic Indexing)の持っていた計算上の制約(最大文書数、最大辞書単語数、演算時間)を大幅に緩和する目的でSDD(Semidiscrete Matrix Decomposition,演算にはSDDPack(http://www.cs.umd. edu/users/oleary/SDDPACK/)を利用)とLSIの組合せによる検索システムを開発。既開発のものに比べ、インデクス演算速度が約80∼100倍となり、同時に100万文書、辞書サイズ50万単語でも実用的に演算できる。
- これまでの茶筅標準辞書,農業専門語辞書(平成10年成果情報)に加え,専門用語自動抽出システム(http://www.forest.eis.ynu.ac.jp/Forest/ja/term-extraction.html)を利用して,専門語辞書の充実をすることで、検索精度の向上ができる。
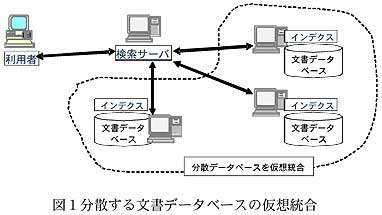
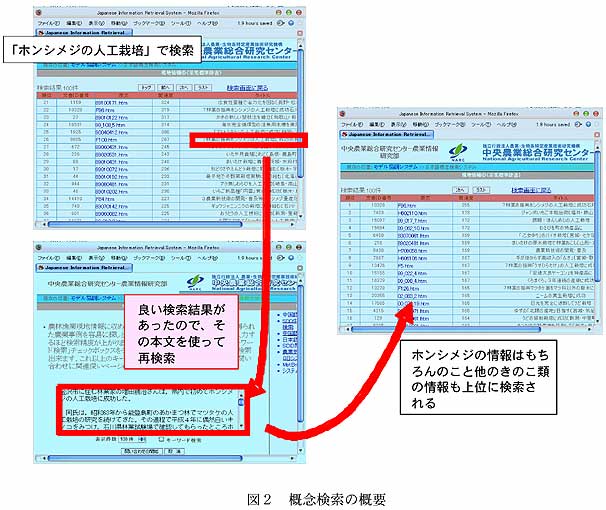
- 文書データベースのサイズを最大5万文書に分割し、かつデータベースは異なるサーバに分散配置が可能であるようアーキテクチャを実現する(図1)。インデクス生成や検索はそれぞれのデータベース毎に行い、検索サーバは結果をとりまとめてクライアントに返す(図2)。データベースサイズを5万文書程度に細分化することで、インデクス生成のための総計時間が20万文書、10万単語の場合で、50分の1と大幅に短縮すると同時に、行列の小型化で検索精度も向上する。
成果の活用面・留意点
- 対象文書群として「農林水産現地情報」、「成果情報」、「レクラス」、「有機・自然農法DB」、「病害虫生理障害情報」をサンプルに試験公開(http://pc110.narc.affrc.go.jp/ AgrInfo/)。
- 公開・非公開を問わず試験運用したい文書群(コーパス)がある場合は、担当者に連絡する。
具体的データ
その他
- 研究課題名:農業・水産情報テキスト知識ベース構築技術の開発
- 課題ID:03-04-01-01-14-05
- 予算区分:委託プロ(協調システム)
- 研究期間:2004∼2005年度
- 研究担当者:二宮正士、孟 紅岩、深津時広、法隆大輔、大塚 彰
- 発表論文等:Meng et al. (2004) CIGR2004, Beijing, Extened Abstracts