文書から自動抽出した用語を選別する方法
※アーカイブの成果情報は、発表されてから年数が経っており、情報が古くなっております。
同一分野の研究については、なるべく新しい情報を検索ください。
要約
農業関連文書を対象としたテキストマイニングでの利用を想定して、文書から自動抽出した用語をさらに選別する方法を開発する。対象とする分野の2種類の文書群を用意すれば、自動で用語の選別が行える。
- キーワード:用語、自動抽出、選別、文書群
- 担当:中央農研・データマイニング研究チーム
- 連絡先:電話029-838-7176
- 区分:共通基盤・情報研究
- 分類:研究・参考
背景・ねらい
テキストマイニングは、大量のテキストデータを分類、要約したり、統計的な処理を行うことによって、そのテキストデータの中にど
のようなことが書かれているか簡潔に提示するための一連の技術である。多くのテキストデータが蓄積されるようになったことから、テキストマイニングの技術
が重要になっている。テキストマイニングでは、テキスト中の単語を認識する過程があり、このとき辞書が参照される。この辞書に専門分野の用語が含まれてい
る方が、テキストマイニングの結果が良くなる場合があるが、専門分野の用語を集めることは容易ではない。
既存の自動抽出の技術を利用すれば、文書から用語を自動で抽出できる。これを利用して、テキストマイニングで対象とする分野の用語を事前に用意し、辞書に
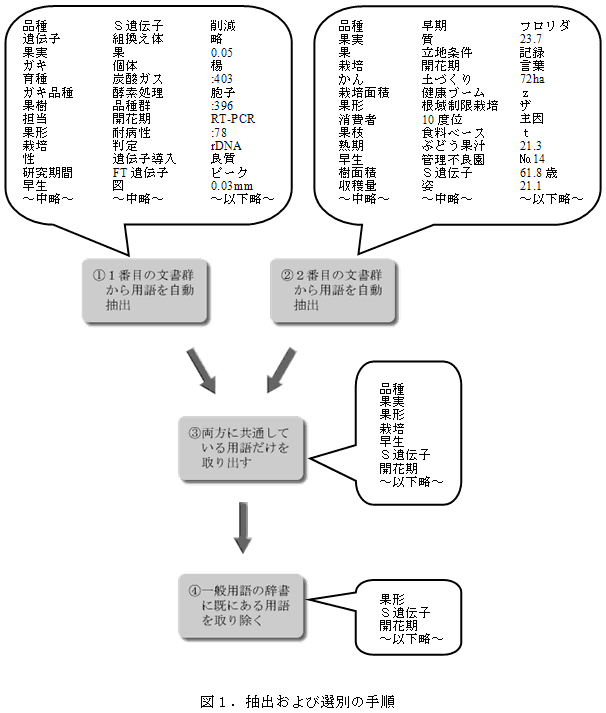
含めておくこともできる。しかし、この方法で抽出を行っただけでは、語の断片や無意味な文字列などが含まれていて、そのままでは利用できない。例えば、図1の右上は果樹に関する文書を対象に用語の自動抽出を行った例であるが、「かん」、「ザ」などの意味不明な文字列が多数含まれている。したがって、利用の前に何らかの選別を行い、こうした意味不明な文字列を排除する必要がある。このような選別を自動で行う方法を開発する。
成果の内容・特徴
- 開発した選別の手順は図1に示した通りである。1番目の文書群から抽出された用語と2番目の文書群から抽出された用語の両方に共通した用語だけを取り出す(図1の手順の3)ことで、語の断片や無意味な文字列を排除することができる。また、一般用語の辞書に既にある用語を取り除く(図1の手順4)ことで、対象とする分野に関係のない用語を排除する。
- 図1に示した実験的な選別では、文書群としてインターネット上のテキストとこの成果情報を用いた。
- 選別によって語の断片などを完全に排除できる訳ではなく、一部に無意味な文字列(例えば、「ゅ病」、「g」など)も残ることがある。
- 選別される語数は、文書群の大きさに依存する。すなわち、選別後に残る用語を増やすためには、文書をより多く収集する必要がある。
- 文書群の収集を除けば、選別の過程において主観による判断は入らない。
成果の活用面・留意点
- 実験的に選別を行った結果については、http://cse.naro.affrc.go.jp/horyu/ko/からダウンロードできる。単語認識ソフトウェアの辞書形式のファイルも用意されているので、単語認識ソフトウェアでそのまま利用できる。
- 自動抽出を行う部分については、既存の他のソフトウェアを利用する必要がある。また、一般用語の辞書も既存のものを利用する必要がある。
- 人手による用語の選別の補助的手段としても有効である。
具体的データ
その他
- 研究課題名:多様かつ不斉一なデータの融合によるデータマイニング技術の開発
- 課題ID:222-c
- 予算区分:基盤
- 研究期間:2006~2007年度
- 研究担当者:法隆大輔、二宮正士
- 発表論文等:Horyu D. and S. Ninomiya (2007) Agricultural Information Research 16(2):52-59.