ノンパラメトリック手法による高精度群判別
※アーカイブの成果情報は、発表されてから年数が経っており、情報が古くなっております。
同一分野の研究については、なるべく新しい情報を検索ください。
要約
核関数を用いるノンパラメトリックな群判別法は、適当な方法で最適ウインドウ幅を決定することにより、通常使用されているパラメトリックな判別方法より有効なものになる可能性がある。
- キーワード:ノンパラメトリック群判別、核関数、ウインドウ幅
- 担当:中央農研・データマイニング研究チーム
- 代表連絡先:電話029-838-8948
- 区分:共通基盤・情報研究
- 分類:研究・参考
背景・ねらい
核関数を用いたノンパラメトリックな多次元密度関数の推定は、密度関数の推定が目的である場合は、高精度推定が困難であるため利用されることが少ないようである。密度関数推定が目的ではなく、群判別を目的とする(推定された密度関数を群判別に利用する)場合の有効性を検討する。
成果の内容・特徴
- 核関数を用いたノンパラメトリックな群判別では、ウインドウ幅により結果が異なり、最適なウインドウ幅を求めることが必要であるが、密度関数推定において平均2乗積分誤差の不偏推定値に関係づけられる指標M0(h)を用い、これが最小になるhを用いる方法が利用可能である。
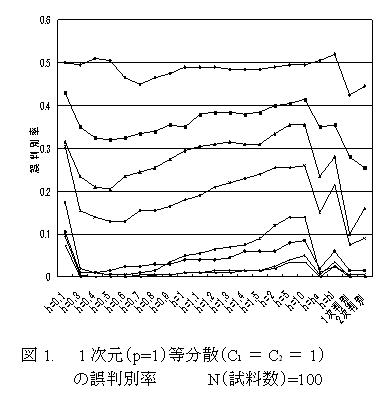
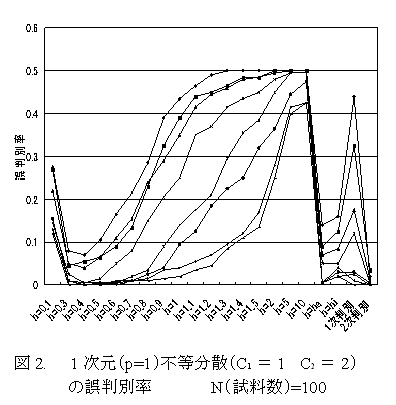
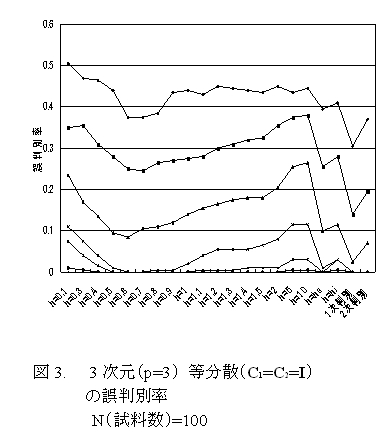
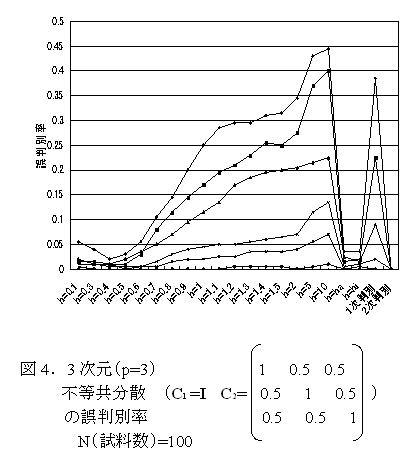
- ウインドウ幅hの最適値決定方法の有効性確認のため、以下の手順を用いる。 [1]2つのp次元正規分布Np(μ1, C1)と Np(μ2, C2)より各N個の試料をとり、既知群データとする。各既知群毎にhの種々の値でM0(h)を計算し、M0(h)を最小とするhi (i=1,2 第1群及び第2群に対応), 及びha=(h1+h2)/2を求める。核関数はp次元標準正規分布の密度関数を用いる。 [2]Np(μ1, C1)と Np(μ2, C2)より各N個の試料をとり、未知群データとする。hの種々の値([1]で求めたh1,h2,haを含む)について 既知群データからhを用いて推定された密度関数を用いて未知群の判別分析を行う。また、パラメトリックな1次、2次判別も行う。 [1][2]をR回繰り返し、誤判別率(計2R個の未知群のうち 誤判別されたものの割合)を 各h値 及び パラメトリックな1次, 2次判別について求める。
- シミュレーションの結果 N=100 μ1=0 R=100 μ2=d1p とし、d=2群間距離/p1/2 の各値に対する ノンパラメトリック、及びパラメトリック判別の各方法による結果(誤判別率)を図1~4 に示す。各方法ともdが大きくなるにつれて誤判別率は減少する。 h=hi (i=1,2), h=ha (各既知群データ毎に変動)を用いた場合の誤判別率は 既知群のM0(h)と無関係に一定のh値を用いた場合の誤判別率の最小値に近い値をとるので、hi,haを最適hとして使用可能である。分散共分散行列が異なる場合(図2, 図4)では、特にhによる変動が大きく、この最適hの決定法の有効性がより明確に示される。また、この場合パラメトリック2次判別も有効である。
成果の活用面・留意点
群データを用いた判別分析(例 米粒の形状パラメータによる品種、産地判別)に活用可能。
具体的データ
その他
- 研究課題名:多様かつ不斉一なデータの融合によるデータマイニング技術の開発
- 中課題整理番号:222c
- 予算区分:基盤
- 研究期間:2007~2009年度
- 研究担当者:山本博道