文章データ活用のためのテキストマイニング用データファイル作成手順
※アーカイブの成果情報は、発表されてから年数が経っており、情報が古くなっております。
同一分野の研究については、なるべく新しい情報を検索ください。
要約
文章データからの情報抽出を可能にするテキストマイニングを実施するためのデータファイル作成手順を開発した。ファイル作成にはフリーソフトウェアの形態素解析ツールと市販の表計算ソフトおよびマクロを利用しており、低コストで簡便な手法である。
- キーワード:テキストマイニング、文章データ、形態素解析、二値データ化
- 担当:東北農研・総合研究部・動向解析研究室
- 連絡先:電話019-643-3491、電子メールisojima@affrc.go.jp
- 区分:東北農業・経営、共通基盤・経営
- 分類:技術・参考
背景・ねらい
農家や消費者を対象とする調査で得られる自由記述回答文や、農産物に関する消費者からのクレームなど大量の文章データは、これまで有効な分析手段がなく活用されることが少なかった。近年、文章データからの情報抽出を可能にするテキストマイニング手法が注目されるようになったが、市販のソフトウェアの多くは非常に高額(数百万円レベル)であり、農業現場で気軽に利用できる状況にはない。そこで、高価なソフトウェアを購入せずにテキストマイニングを実施するためのデータファイル作成手順を開発する。
成果の内容・特徴
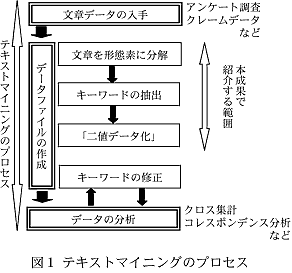
- テキストマイニングの全体的なプロセスは、(1)文章データの入手、(2)データファイルの作成、(3)データの分析、という流れで行う(図1)。本成果では、このうちの「データファイルの作成」の部分を開発した。
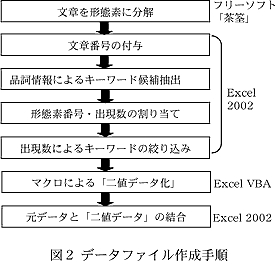
- データファイルの作成手順は以下の通り(図2)。(1)文章データを「茶筌(ちゃせん)」を用いて形態素(意味を有する最小の言語形態)に分解する。(2)分解された形態素がどの文章に含まれていたかを明示するために、各形態素に文章番号を付与する。(3)各形態素の品詞情報からキーワードの候補となる形態素を抽出する。(4)抽出した形態素は、基本形が同じである語をまとめて形態素番号と出現数を割り当てる。(5)この出現数を基準にしてキーワードの絞り込みを行う。(6)各文章において、これらキーワードが出現している場合には1、出現していない場合には0を出力する「二値データ化」を行う(マクロを使用)。(7)作成した「二値データ」を元の文章データと結合する。
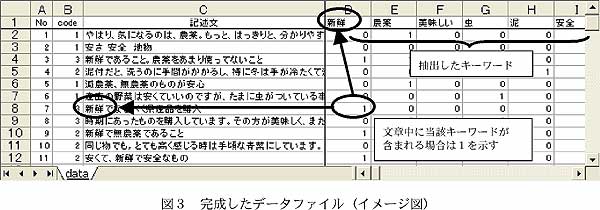
- 完成したデータファイル(図3)は、文章データに含まれるキーワードの有無を0・1のカテゴリカル変数として示すので、出現頻度の算出だけではなく、より高度な統計分析を行うことが可能である。
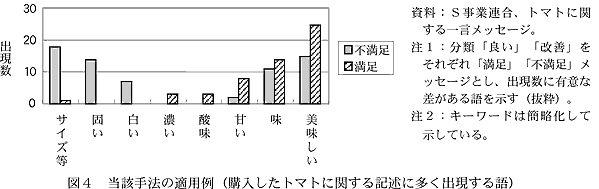
- 本手法を適用して、農産物を購入した消費者の評価を分析(図4)すると、トマトに関する記述(128件)のうち、満足している消費者は「美味しい」「味」「甘い」「酸味」「濃い」などの言葉を、不満足な消費者は「白い」「固い」および「サイズ」などの言葉を記入しており、これらが優先的に改善を必要とするポイントであることがわかる。
成果の活用面・留意点
- Excel 2002のオートフィルタ機能を用いれば、キーワードによる文章データの分類・整理に活用することも可能である。
- 本手法の有効性については、平成15年度「主要研究成果」で紹介している。
- 詳細な作業手順およびマクロのコードについては東北農研総合研究(B)第19号を参照のこと。なお、マクロはFD等で配布可能である。
- 「茶筌」は奈良先端科学技術大学院大学自然言語処理学講座が提供しているフリーソフトウェアである。詳細はhttp://chasen-legacy.sourceforge.jp/ を参照のこと。
具体的データ
その他
- 研究課題名:市場・消費動向把握のためのデータ収集・解析手法
- 課題ID:05-01-07-01-04-03
- 予算区分:寒冷気象利用
- 研究期間:1999~2003年度
- 研究担当者:磯島昭代、野中章久
- 発表論文等:1) 磯島(2004)東北農研総合研究(B)19:1-55.
2) 磯島ら(2004)農業経営研究42(1):148-151.