テキストマイニングにおける文章データ二値化ファイルの自動作成システム
※アーカイブの成果情報は、発表されてから年数が経っており、情報が古くなっております。
同一分野の研究については、なるべく新しい情報を検索ください。
要約
テキストマイニングを行う際には、文章中のキーワードの有無を二値で示すデータファイルの作成が必要であるが、Excelのシート上で文章データの範囲を指定し、抽出する品詞を選択するだけで、このファイル作成を自動的に実行できるシステムを構築した。
- キーワード:テキストマイニング、MeCab、文章データ、二値化
- 担当:東北農研・東北地域活性化研究チーム(兼:中央農研・マーケティング研究チーム)
- 代表連絡先:電話019-643-3494
- 区分:共通基盤・経営、東北農業・基盤技術(経営)
- 分類:研究・参考
背景・ねらい
これまで、文章データの数量的な分析を可能にする簡易なテキストマイニング手法を提案し、同手法が農産物に対する消費者ニーズ解明などに有効であることを示してきた。しかし、従来のシステムではテキストマイニング実施に必要なデータファイル作成の手順において自動化された部分が少なく、前処理段階の作業量の多さや作業の煩雑さが同システムの普及を阻害していた。そこで、このデータファイル作成手順全体を自動化するマクロを作成し、より利用しやすいシステムを構築する。
成果の内容・特徴
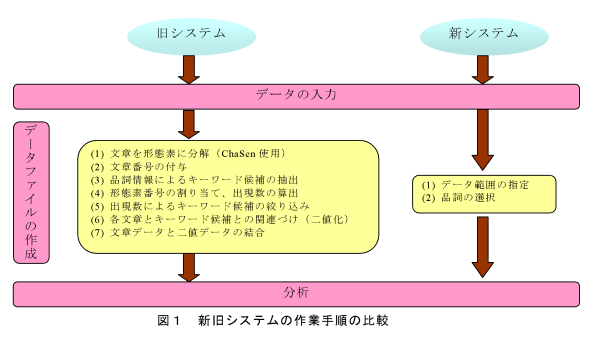
- 簡易版テキストマイニングにおいて文章データを数量的に分析するために、文章中のキーワードの有無を1・0の二値で示すデータファイルの作成が必要となるが、新システムではこのデータファイル作成の過程を全てマクロで自動化し、必要な作業は(1)Excelのワークシート上にある文章データの範囲指定と、(2)キーワード候補として採用する品詞の選択のみとなる(図1)。旧システムでは、図1の(1)~(7)の過程で自動化しているのは「(6)二値化」の部分のみであり、この他は条件式の入力やコピー/ペーストなど多くの作業が必要とされたが、それらが全て自動化されたことになる。
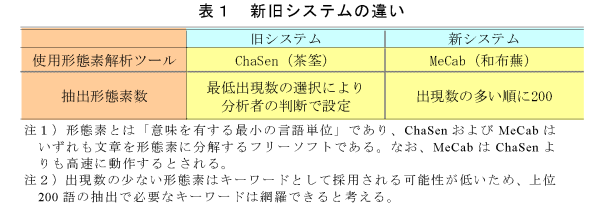
- 新システムの特徴は、形態素解析ツールとしてMeCabを採用している点である。また、これまでキーワード候補として採用する形態素の数は、出現数を基準として分析者の判断で設定することになっていたが、新システムでは操作の簡略化のために出現数の多い順に200個と固定している(表1)。
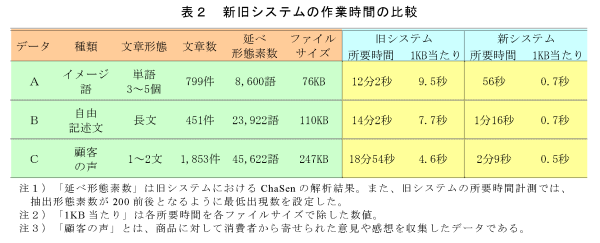
- 旧システムと新システムの作業時間を計測した結果、ファイルサイズの大きさによって多少の差はあるが、旧システムの所要時間が10~20分程度(1KB当たり4~10秒)であるのに対し、新システムでは1~2分程度(1KB当たり0.5~0.7秒)と飛躍的に向上している(表2)。なお、これは旧システムに熟練した作業者による結果であり、初心者が旧システムでマニュアルを読みながら作業を行う場合には、所要時間のさらなる増加が予想され、新システム導入による時間短縮効果は絶大なものとなる。
成果の活用面・留意点
- アンケートの自由記述文など大量の文章データを数量的に分析する際に活用できる。統計分析には別途統計処理用ソフトが必要であるが、文章中の頻出語の抽出や、キーワードを含む文章の確認などは、本システムとExcelの利用で簡単にできる。
- システムの実行には、フリーソフトMeCab ver.0.98(http://mecab.sourceforge.net/)のインストールが必要。動作確認環境はOS:Windows XP、Excel:Excel2000、Excel2002、Excel2007。
- 新システムのマクロ入手方法および簡易版テキストマイニングの関連成果、旧システムの作業手順などに関する詳細は、http://narc.naro.affrc.go.jp/soshiki/mrt/result.htmlを参照のこと。
具体的データ
その他
- 研究課題名:消費者・実需者ニーズを重視した農産物マーケティング手法の開発
- 中課題整理番号:311i
- 予算区分:基盤
- 研究期間:2009年度
- 研究担当者:磯島昭代、大浦裕二、山本淳子