雑草埋土種子量の推定精度と検出力
要約
埋土種子調査の目標推定精度D =0.4では、2つの平均値間に8倍の違いがあると、9割程度の確率で有意差(p=0.05)として検出しうるが、4倍の違いであると7割程度の検出力となる。反対に2倍の違いを確実に検出するためには、D =0.1の精度が必要である。
- キーワード:雑草、埋土種子、検出力、推定精度、必要サンプル数
- 担当:東北農研・東北水田輪作研究チーム
- 代表連絡先:電話019-643-3585
- 区分:共通基盤・雑草、東北農業・作物(畑作物栽培)
- 分類:研究・参考
背景・ねらい
埋土種子量の把握は、合理的な雑草管理を設計する上で、また雑草の個体群動態を解明する上で重要性が高まっている。国内においては、埋土種子量を推定する際の目標推定精度の指標として相対標準誤差![]() が一般に用いられている。 Dは分布の正規性を前提としないことから、埋土種子数のような離散変量を対象とした小サンプルのデータに対しても定義可能である。 Dの値については、大まかな鳥瞰的研究では0.3~0.4、詳細な、例えば生命表解析を目的とするような研究では0.1~0.2といった一応の目安は示されているが、平均値に対する信頼区間の比である標本誤差率
が一般に用いられている。 Dは分布の正規性を前提としないことから、埋土種子数のような離散変量を対象とした小サンプルのデータに対しても定義可能である。 Dの値については、大まかな鳥瞰的研究では0.3~0.4、詳細な、例えば生命表解析を目的とするような研究では0.1~0.2といった一応の目安は示されているが、平均値に対する信頼区間の比である標本誤差率![]() ほどは直感的でない。そこでランダムな種子の空間分布を仮定したシミュレーションを行い、2つの平均値の様々な組み合わせについて、目標精度D と必要サンプル数および検出力との関係を明らかにする(式中のq はサンプル数、 tは自由度q-1 のt- 分布の両側
ほどは直感的でない。そこでランダムな種子の空間分布を仮定したシミュレーションを行い、2つの平均値の様々な組み合わせについて、目標精度D と必要サンプル数および検出力との関係を明らかにする(式中のq はサンプル数、 tは自由度q-1 のt- 分布の両側![]() 点、m は土壌サンプルに含まれる平均種子数の標本推定値、 sは標準偏差の標本推定値である)。
点、m は土壌サンプルに含まれる平均種子数の標本推定値、 sは標準偏差の標本推定値である)。
成果の内容・特徴
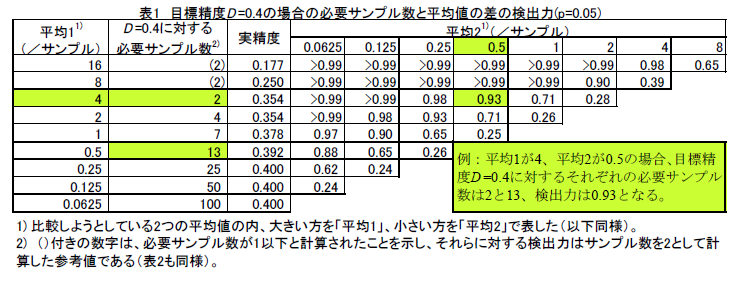
- 大まかな鳥瞰的研究の目標精度とされるD =0.4では、平均値間の違いが8倍あると9割程度の確率で有意差(p=0.05)として検出しうるが、4倍の違いであると6~7割程度の検出力となり、第2種の誤りを犯す確率が3割程度ある(表1)。
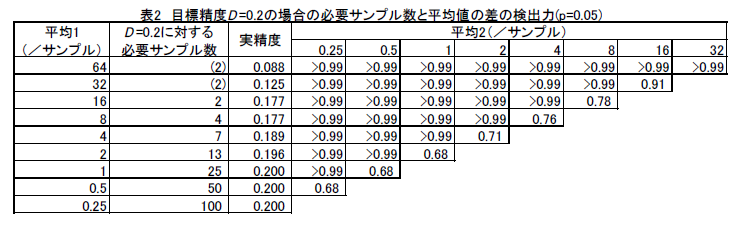
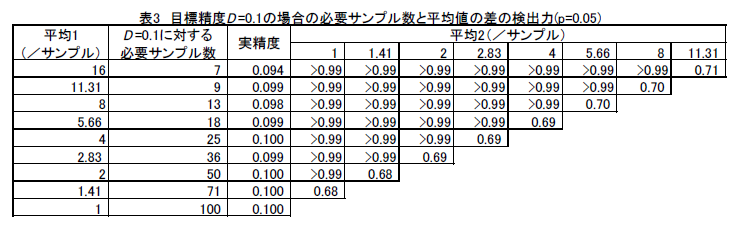
- D=0.2では、4倍の違いはほぼ確実に検出できるが、2倍の違いであると7割程度の検出力となる(表2)。同様に、 D=0.1では2倍の違いをほぼ確実に、1.41倍の違いで7割程度の検出力となる。すなわち2倍の違いを確実に検出するためには D=0.1を目標精度としなければならない(表3)。
- 以上の精度D の値と検出力の関係は平均値の値が変化してもほぼ維持される。(表1、表2、表3)。
成果の活用面・留意点
- 現地の埋土種子調査や埋土種子の動態に関する実験において、サンプリングまたは実験計画の際に活用が期待される。
- 本成果では、埋土種子が空間的にランダムに分布することを仮定し、土壌サンプルに含まれる種子数をポアソン乱数でシミュレートした。平均値の異なる2つの乱数を発生させ、その様々な組み合わせについてポアソン回帰によりそれぞれ100000回検定を行い、有意となった回数を総検定回数100000で割った値を検出力とした。
- 雑草の埋土種子は一般に集中分布するが、複数の土壌サンプルの混合や、調査対象圃場に関する事前情報があり、想定される種子量により層化が可能な場合は層別サンプリングを行うことにより、ランダムな分布に近づけることは可能である。
- 詳細は発表論文を参照されたい。
具体的データ
その他
- 研究課題名:地域条件を活かした高生産性水田・畑輪作のキーテクノロジーの開発と現地実証に基づく輪作体系の確立
- 中課題整理番号:211k.3
- 予算区分:基盤、交付金プロ(総合的雑草管理(IWM))
- 研究期間:2007~2010 年度
- 研究担当者:中山壮一、柴田宙泰(横浜国立大学)、浅井元朗
- 発表論文等:中山ら(2011) 雑草研究、56(1):53-61